I have converted yet another googlecode Mercurial repository to Git – and as it took me (again) a bit too much time, here is my recipe:
Prepare
Log into a Linux shell (Windows will hardly work – at least it didn’t work for me). If you don’t have some remote shell, download an Ubuntu VM and fire it up (you might need to install VirtualBox if you haven’t installed it already).
Check out your HG repo:
hg clone https://code.google.com/p/MyHgProject/
Check if you have to remap some author information:
hg log MyHgProject
If you want/have to remap, simple create an author map file
oldemail@example.com=Firstname Lastname
Convert
Get fast-export and convert your repo:
git clone git://repo.or.cz/fast-export.git
mkdir new_git_repo
cd new_git_repo
git init
/path/to/hg-fast-export.sh -A ../authormap -r /path/to/MyHgProject
git checkout HEAD
Push
Now change the source setting in your google code repository to git and push the local codebase:
git remote add origin https://code.google.com/p/MyHgRepo/
git push --all
At this point, your upload might fail with something like “error: RPC failed; result=35, HTTP code = 0”.
This can happen if your upload takes too long and this is a documented bug.
I simply solved this issue by pushig the git repo from a shell with a fast enough upload speed as my local connection obviously was too slow.
Wiki
Now you might realize that you have “lost” your complete wiki – don’t worry, it’s still there!
Switch back your repo setting to Mercurial and repeat the process for your wiki which you can usually find at https://code.google.com/p/yourProjectName/source/checkout?repo=wiki
That’s it. You should now be ready to use Git!
Thanks to following sites hedonismbot, scrambled tofu
 Then change to the Windows-Tile screen (just hit the Windows-Key on your keyboard) and type “Epson Scan”. A list should appear that shows the Epson Scan entries. One of them should be “Epson Scan Settings” (german: Epson Scan-Einstellungen).
Then change to the Windows-Tile screen (just hit the Windows-Key on your keyboard) and type “Epson Scan”. A list should appear that shows the Epson Scan entries. One of them should be “Epson Scan Settings” (german: Epson Scan-Einstellungen).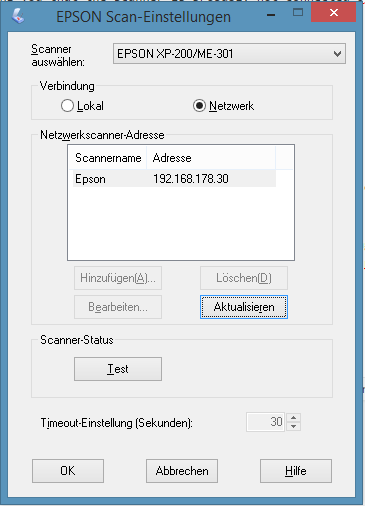
 The scan software should work now. I first had some issues that I also had to run it with admin privileges. Sometimes I could start the scanning software, showing the correct user interfacec but it only scanned a very tiny part of the physical scan area (VERY strange).
The scan software should work now. I first had some issues that I also had to run it with admin privileges. Sometimes I could start the scanning software, showing the correct user interfacec but it only scanned a very tiny part of the physical scan area (VERY strange).